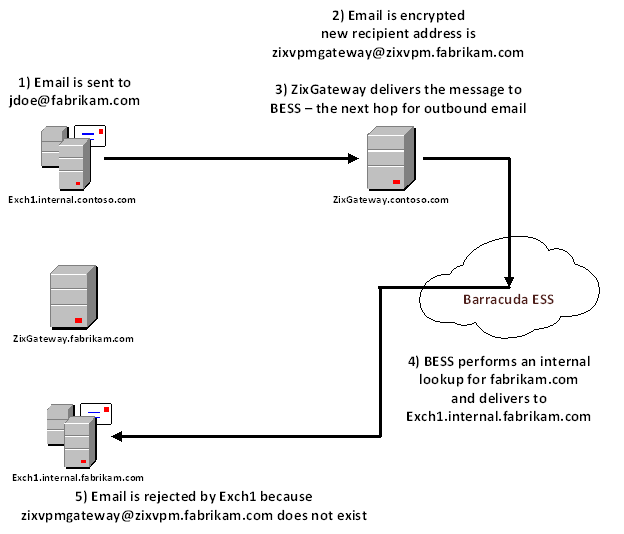
Since Veritas took over Backup Exec from Symantec, we’ve had issues getting licensing migrated and renewed for various reasons.
For one customer we had recently renewed maintenance for one year and needed to apply the license to the Backup Exec console. In the console, I could see there were product licenses and maintenance licenses. The maintenance licenses had indeed expired.
When I went to the Veritas licensing portal to retrieve the licenses, they showed an expiration date in one year from now. I downloaded the new licenses, but no matter what I tried to import or delete existing licenses, it never would display the new maintenance expiration dates.
I called Veritas and they changed the way maintenance licenses are managed from the Veritas portal; they are not managed on the Backup Exec console any longer. You can ignore the dates for the maintenance contract now since they moved over to Veritas.