
One of our customers is using an MPLS network for their WAN connections. but they have installed backup Internet connections at their branch locations in order to maintain connectivity to the corporate office if one of the MPLS connections was to fail. See the diagram below for reference:
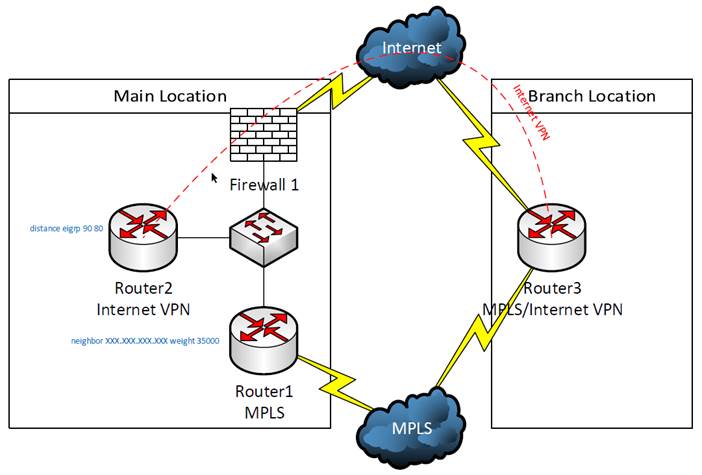
In order to configure the backup VPN, a VPN tunnel must be built between the main location and the branch location, in this case Router2 and Router3, respectively. Also, GRE tunnels were built between these routers so that routes could be dynamically exchanged using EIGRP, which also requires adding static routes for the GRE tunnel interfaces to route this traffic out the Internet connections instead of over the MPLS connection. All routers participate in the same EIGRP process. BGP and EIGRP are redistributed into each other on Router1. The EIGRP routes will not be preferred on the branch router (Router3) because EIGRP has a higher administrative distance (90) than BGP (20) and the BGP routes will be used. On the Internet VPN router (Router2), these routes will be preferred because EIGRP internal has a lower administrative distance (90) than external EIGRP (170). This behavior can be changed by adding the “distance eigrp DesiredInternalAdminstrativeDistance DesiredExternalAdminitrativeDistance” (“distance eigrp 90 80” in this case) command to the EIGRP configuration.
This setup will work for failover, but will additional configuration is needed for the router to automatically failback to the MPLS connection. If the failure is at Router3, Router3 will return to using BGP routes from MPLS when the connection is restored. By default, Router1 will continue to use the routes obtained via EIGRP because the weight of these injected routes of 32768 is greater than the default weight of 0 for learned routes. This can be resolved by setting the learned routes from the BGP neighbor (ISP) to a higher weight than the injected routes. In this case, “neighbor NeighborIPAddress weight 35000” was added to the BGP configuration on Router1. These higher weight routes overwrite the injected routes.
The combination of changing the administrative distance in EIGRP and BGP neighbor weights allows this connection to fail to the Internet VPN and return to the MPLS connection dynamically.