
As more and more offerings are moved into the cloud under subscription-based licensing, it's both becoming easier for people to take advantage of software that previously may not have been as readily available, and more challenging to find a solution that doesn't involve storing your data one someone else's hardware.
Office 365 is a great example of this as it really does seem like the writing is on the wall for non-subscription licensing of the Office Suite for on-prem installation of much of the server software platform. Granted, Microsoft does make it remarkably easy to just switch over to their platform and to use all the pieces of the software suite that have been designed to seamlessly work together, but there is always a concern (even if it's tiny) that your data is in someone else's hands.
Let's look at cloud hosting from a data availability vantage point instead. The cloud makes it incredibly simple to access the platform from practically anywhere in the world – provided thie service is online. In early February 2020, there was a global outage of the Microsoft Teams platform which brought a lot of this to light. If you were already logged in prior to the outage, you were good to go. Anyone else trying to connect up after the fact was in trouble.
The cause of the outage? https://twitter.com/MSFT365Status/status/1224351597624537088
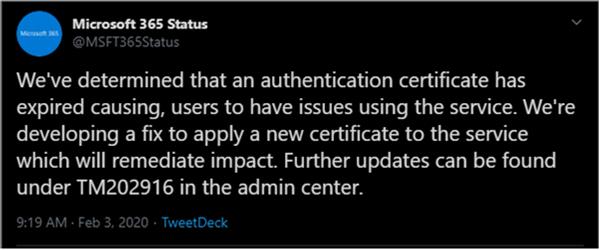
That's right, even an incredibly large organization that spends billions every year, such as Microsoft, can forget to renew their certificates occasionally. Within a few hours, the renewed certificate was deployed across their vast infrastructure and the Teams service was brought back online. While I doubt that this certificate will ever be forgotten in the future, maybe Microsoft should take the advice of one of the responders to their announcement. https://twitter.com/nunu10000/status/1224353813987053568?s=20

As a consumer, my biggest takeaways are this:
The Good: The Office 365 platform is always up-to-date. Any security vulnerabilities are likely patched within a matter of hours rather than waiting on a change window once a month. New features are released regularly.
The Bad: Any outage on-prem and I have a general idea how long things will take to bring it back online. With cloud services, any outage is at the whim of the service provider.
The Ugly: Knowing the above, once you're on-boarded onto a specific platform, it's usually impractical to evacuate that platform and move to another with any sort of regularity. What is the magic number for downtime to make it worth the cost of migrating services? What about if you were unable to easily or cheaply move existing data off that platform during the migration (i.e. online archive/journaling solutions)?

