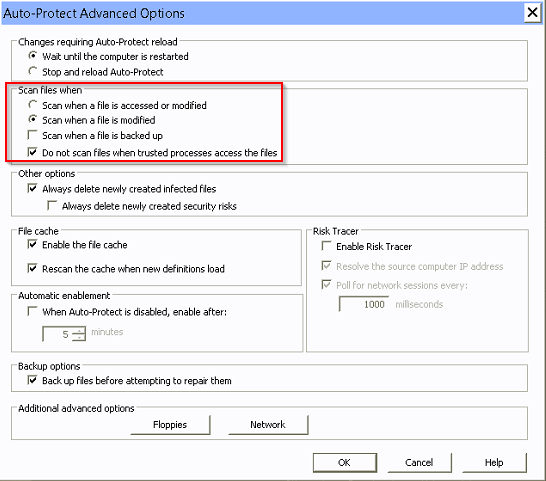
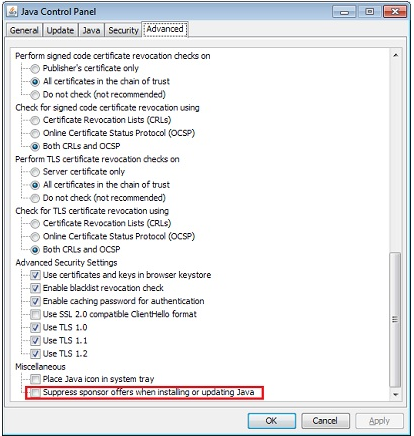
If Outlook says "This file cannot be previewed because there is no previewer installed for it" when you are trying to preview an attachment, this means that file type has no default program associated with it. Try saving the attachment and then choose Open With... to associate a program. After that, Outlook will use that program to preview attachment of that file type.
This demonstrates that previewing attachments is the same as opening them, so caution is advised.